AI Agents, Minus the Hype — A Production-Grade Playbook
How to architect, deploy, and monitor resilient LLM-powered automations for B2B SaaS, with reference diagrams, latency budgets, and anonymized benchmark data.
date
author
Engineering Team

Production is the only benchmark that matters.
Table of Contents
- Key Business KPIs
- Reference Architecture
- Deployment Patterns & Stacks
- Evaluation & Monitoring
- Failure Modes & Mitigations
- Operational Metrics — Case Study
- Conclusion
Key Business KPIs
- First-Response Time (FRT)
- Mean Time To Resolution (MTTR)
- Support Backlog Volume
- Net Revenue Retention (NRR)
- Engineering Hours Saved
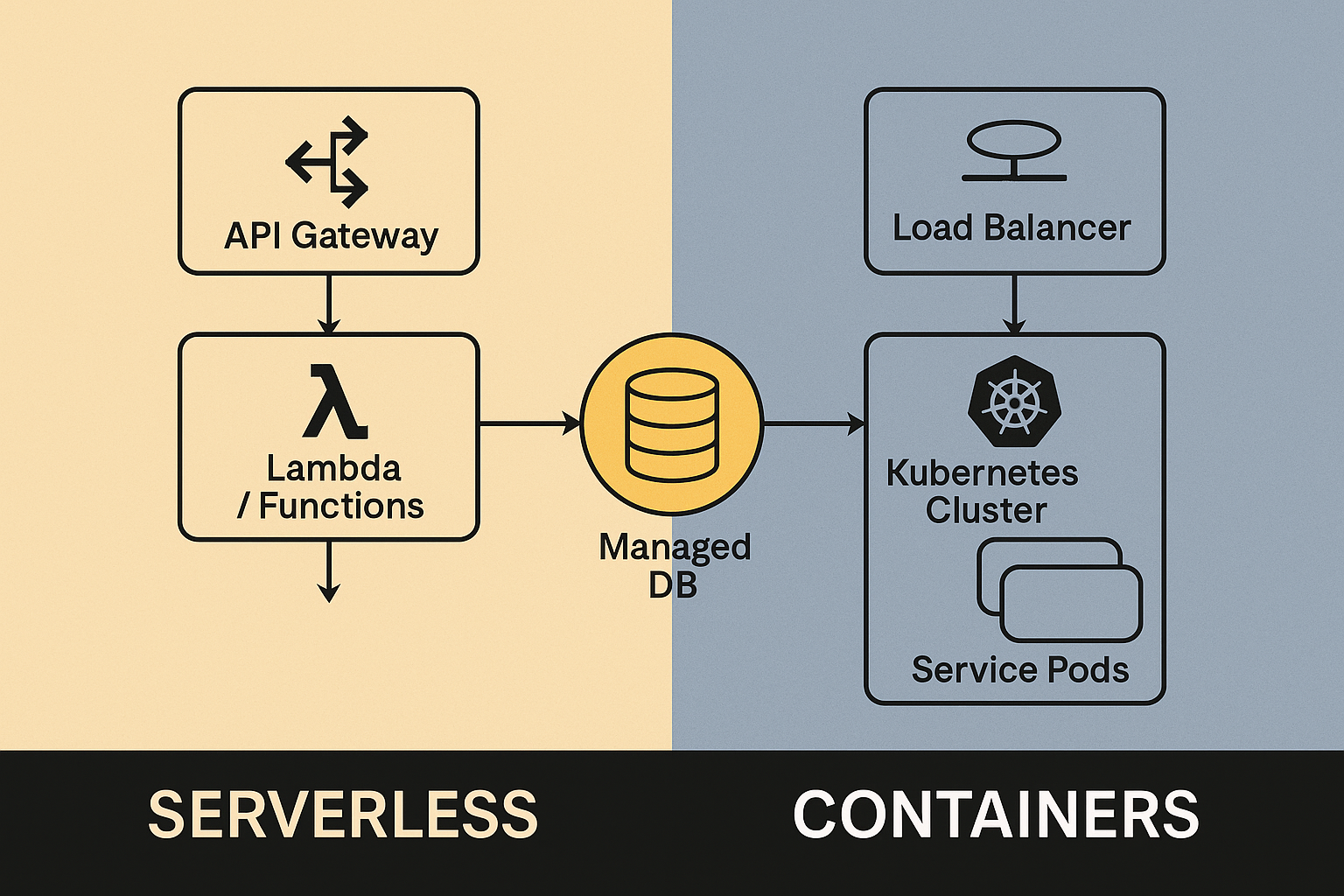
Reference Architecture
flowchart TD
subgraph Client
A[Web / Mobile Client]
end
subgraph Gateway
B(gRPC API Gateway)
end
subgraph Queue
C[NATS JetStream]
end
subgraph Workers
D[Ray Actor Pool]
end
subgraph VectorDB
E[Weaviate Cluster]
end
subgraph LLM
F[GPT-4o or Ollama Server]
end
A -->|HTTP/2| B -->|Async RPC| C --> D
D -->|RAG Query| E -->|Context| F
D <-->|Completion| FDesign Notes
- Stateless Gateway enables zone-aware horizontal scaling via Kubernetes HPA.
- At-Least-Once Delivery enforced by JetStream acknowledgments.
- Vector Search uses HNSW + cosine similarity; median p95 latency ≈ 18 ms.
Deployment Patterns & Stacks
| Pattern | Primary KPI | Recommended Stack | Median Time-to-Prod |
|---|---|---|---|
| Support Auto-Triage | FRT ↓ | LangChain, Weaviate, FastAPI, Argo CD | 3 weeks |
| Data Hygiene Sentinel | Invalid Rows ↓ | Airflow, Pandas, Great Expectations, BigQuery | 4 weeks |
| Content Draft Agent | Writer Hours ↓ | Next.js, Supabase, GPT-4o, LaunchDarkly | 2 weeks |
| DevOps Alert Synthesiser | MTTR ↓ | Kafka, Ollama, Grafana, Thanos | 3 weeks |
Evaluation & Monitoring
- TruLens for pairwise response quality (BLEU + custom rubric).
- LangSmith traces streamed to OpenTelemetry Collector, queried via Grafana Tempo.
- Prometheus metrics:
agent_latency_seconds,prompt_token_total,completion_token_total,guardrail_violations_total. - Alert Rule Example:
rate(guardrail_violations_total[5m]) > 0→ PagerDuty SEV-2.
Failure Modes & Mitigations
| Failure Mode | Symptom | Mitigation |
|---|---|---|
| Prompt Drift | Accuracy degrades | Weekly regression tests with Promptfoo |
| Latency Spikes | p95 > 1 s | Batch embeddings (256/query); enable Redis-LRU cache |
| Cost Overrun | $ / 1 k tokens ↑ | Route non-critical traffic to Glow T-4 |
| PII Leakage | Compliance alert | Regex redaction + Pydantic schema validation pre-dispatch |
Operational Metrics — Case Study
Anonymized mid-market SaaS platform (Series B, ~2.5 k customers).
| KPI | Baseline | 30 Days Post-Launch |
|---|---|---|
| Support Backlog (tickets) | 1 420 | 822 |
| Avg. Handling Time (min) | 18.2 | 9.6 |
| First-Response Time (min) | 42.0 | 8.1 |
| Net Revenue Retention | 113 % | 116.2 % |
Conclusion
LLM-powered agents deliver tangible operational gains—often double-digit efficiency improvements within a single quarter—when built on solid architecture, instrumented rigorously, and governed by clear cost and quality budgets.
Join the list. Build smarter.
We share dev-ready tactics, tool drops, and raw build notes -- concise enough to skim, actionable enough to ship.
Zero spam. Opt out anytime.